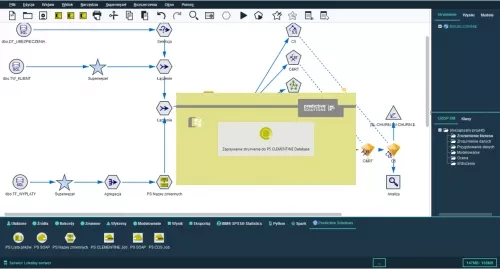
New analytical engine – IBM SPSS Modeler 18.2.1
- A new modern interface.
- Data preview for visualising data flowing through any stream node allowing advanced data visualisations..
- New nodes that utilise Python:
- JSON nodes for importing and exporting data in JSON format.
- Modelling nodes:
- Gaussian Mixture node: a cluster analysis method (a generalisation of K-means Clustering);
- Kernel Density Estimator (KDE) nodes: techniques used to model quantitative variables and for Result Sheet Simulation to estimate the density of variable distribution;
- Hierarchical Density-Based Spatial Clustering (HDBSCAN) node: a technique for the identification of clusters in large data sets using unsupervised learning.
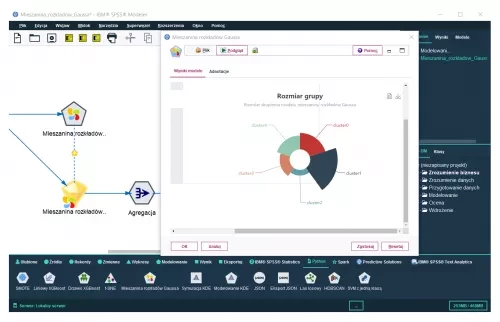
Gaussian distribution
New interface
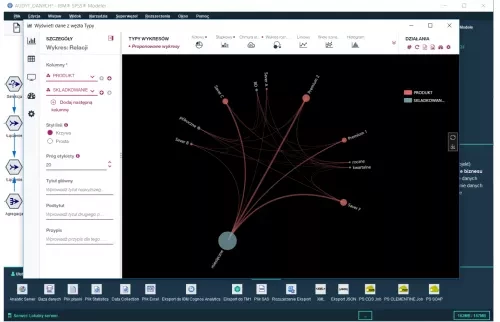
Relationship Chart
Additional nodes in IBM SPSS Modeler:
- PS File List which allows to simultaneously upload and combine several flat files with the same structure.
- PS Variable Names which allows to quickly and easily modify several variable names at the same time.
- PS SOAP Input which captures data from Internet data sources via SOAP webservices.
- PS SOAP Output which sends processed data from a stream to an external web service on the Internet.
- PS CLEMENTINE Job which triggers jobs defined in the repository of PS CLEMENTINE PRO (Central Processing).
- PS CDS Job which triggers a job in IBM SPSS Collaboration & Deployment Services (Central Processing).
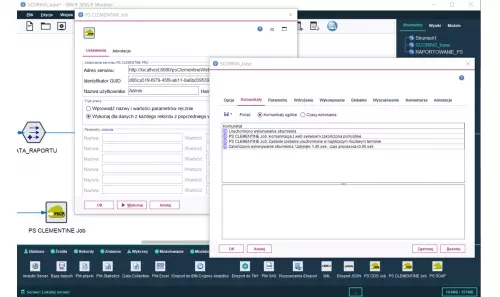
PS Clementine Job
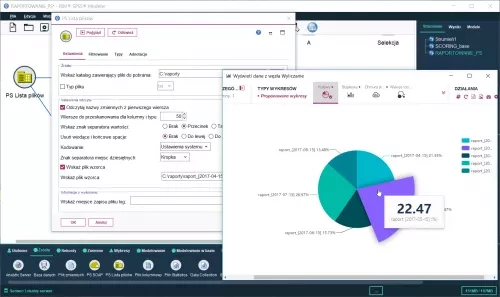
PS FILE LIST
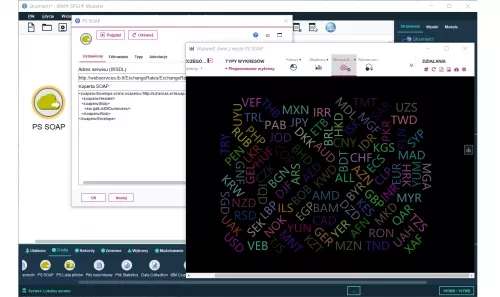
PS SOAP
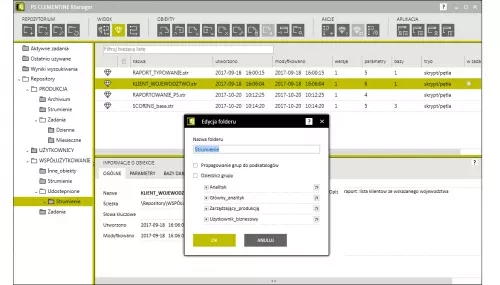
Repository teamwork:
- Access authentication user repository login functionality. They may be added manually or using the catalog service list - Active Directory, which allows to uniformly represent employees in the company systems and control the access to the repository. Communication with Active Directory can be SSL-encrypted.
- Teamwork: possibility of working in groups and to manage the work inside the repository. Users are granted individual access rights and authorization to edit repository items, in accordance with their function. Moreover, it is possible to create roles and user groups.
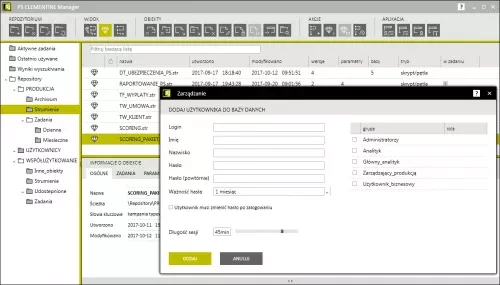
Adding users to the database
Granting access rights
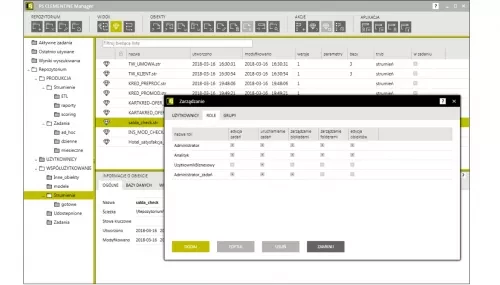
Roles created
New automation functionalities
- New types of automatic triggering of analytical processes depending on occurrence of specific events:
- appearance of a file in a specific directory (the File Monitor task).
- incoming signal from an external system (through web services, Web Service task).
- Option to insert job parameters into the stream of the job when it is being executed:
- full path of the file that triggered the job (for File Monitor jobs),
- task trigger unique id.
- Merging multiple jobs selected in the repository into one. The jobs are automatically added to the created job.
- E-mail notifications concerning task performance status sent automatically to specific persons. Such notifications contain information concerning task performance status (success or failure) and performance details.
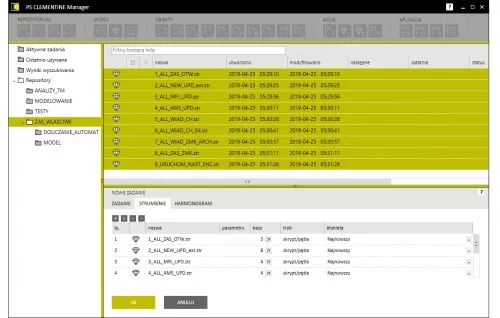
New task

Passing task parameters
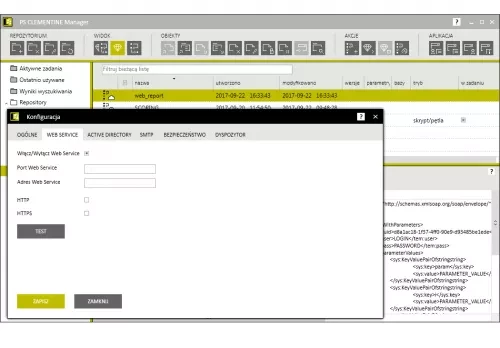
Web Serwice
Management of repository resources
- Labeling of versions of stored items – versioning of items has been enhanced by an additional function – labeling – allowing to identify versions of items in a task in an unambiguous manner. Available labels inform if a given version is intended for implementation (Production), testing (Test), or if it is a version intended for further improvement (Important).
- Import and export of folders – importing and exporting single repository items has been enhanced by a possibility to move folder content (including subfolders and maintaining the structure).
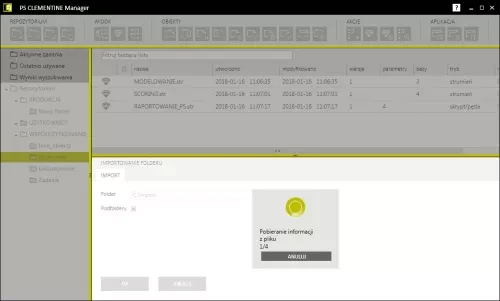
Import
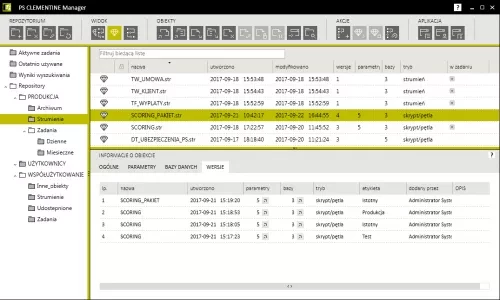
Versioning
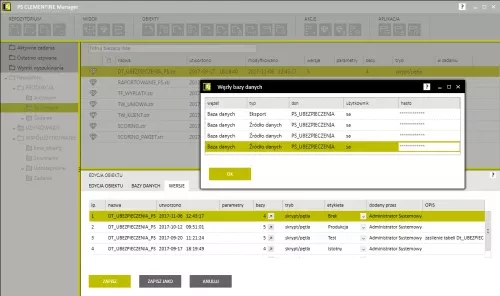
Labeling and communication with databases
Functional improvements
- Improved integration of the repository with IBM SPSS Modeler.
- New function to perform operations in multiple objects simultaneously (multiselect).
- Improved algorithm for finding objects in the repository.
- Enhancements to the analytical process triggering application.
- Extended context menu that includes object versions.
- A new, modernised look to the interface.
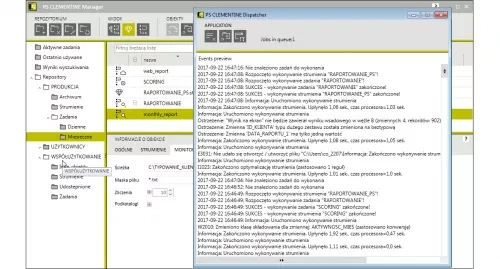
Dispatcher
Operations on many objects