The data preparation process also significantly improves the efficiency of training machine learning models. Prepared and transformed data allows models to be trained faster and more efficiently, which reduces computation time and allows results to be obtained quickly. These are particularly important aspects in the context of large data sets, where optimizing processing time is crucial.
Best practices in data preparation – improving data quality
Data preparation is a key step in data analysis and machine learning processes. Improving data quality requires a number of best practices that help identify problems and optimize data for further analysis. Below, I will discuss some aspects to look out for during the data preparation stage for analysis.
The first important element is the description of variables and the identification of errors. A thorough description of variables should include their name, types, range of values, meaning and units of measurement. Such a description allows analysts to better understand the data. At this stage, some issues in the data can already be caught. These may include inconsistencies in data types, value ranges or missing data that may need to be imputed or deleted. This basic familiarization by the analyst with the data already gives him or her some perspective on the data they will be working with.
Next, a step in preparing the data may be to remove duplicates. These can lead to distortions and erroneous conclusions, so they must be identified and removed. This process involves checking whether the identified duplicates should indeed be removed, and then removing them from the data set.
Another important aspect is data normalization and standardization, which help improve data quality. Normalization transforms data to a common scale, which is especially significant for machine learning algorithms that are sensitive to the scale of the data. Standardization, on the other hand, transforms data so that it has a mean of zero and a standard deviation of one, which can improve the performance of many algorithms.
Filling in missing values is also an important part of data preparation. Missing data can lead to problems in analysis, so it makes sense to fill in missing data using various techniques, such as simple substitution of missing data such as the mean, or to use more advanced algorithms for imputing missing data.
The final element of data preparation can be data categorization, which involves converting numerical data into categories. This is particularly useful for variables that have non-linear relationships or for which numerical values have no logical order.
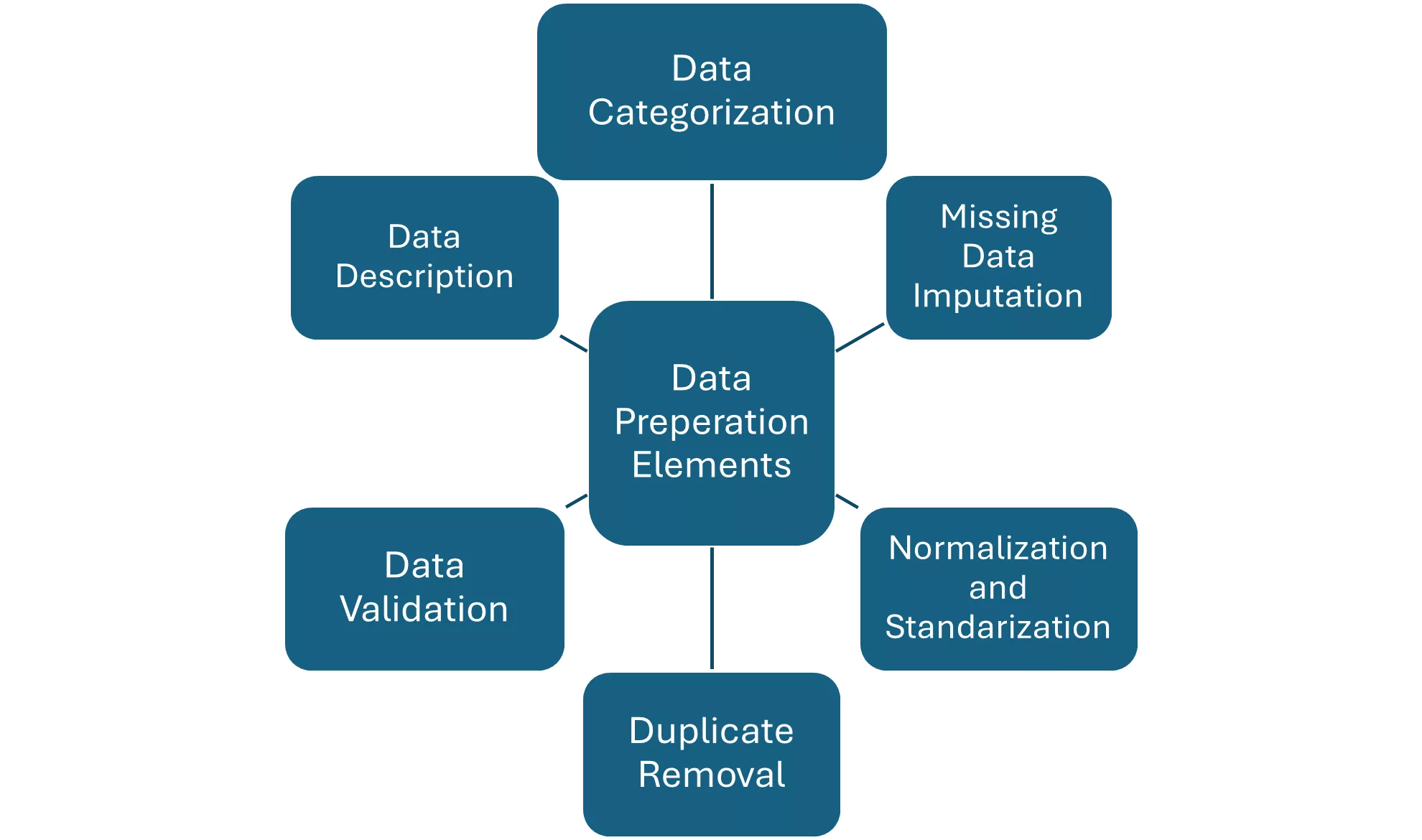
Fig.1 Selected elements of the process of preparing data for analysis
As can be seen, the stage of adequate data preparation for modeling and analysis consists of many elements. In the case of very large data sets, which are also frequently updated, manually preparing them for modeling is virtually impossible. Therefore, it is worthwhile in this regard to use the help of tools and scripts that automate this process, speed it up and ensure its repeatability.
Challenges in manual data preparation
Manual data preparation involves a number of challenges that can affect the efficiency and quality of the process. In addition to the obvious problems, such as time-consuming and subjective decisions, there are several other significant challenges. One of the main difficulties is the lack of scalability. Manual data processing becomes inefficient and difficult to manage when dealing with large data sets. The increase in data volume makes the manual approach inefficient and can lead to errors or omissions. For data with a very large number of predictors, selecting the right ones for modeling and preparing them can be a difficult task.
The lack of standardized methods for working with data is another challenge. Different people may use different methods and approaches to data preparation, leading to inconsistencies. Standardization of data preparation processes is difficult to achieve with a manual approach, which can impact the quality and comparability of results. Human error is inevitable with manual data processing. Even the most experienced analysts can make mistakes that can have serious consequences for data quality and analysis results. These mistakes can result from simple typos, misunderstanding of the data or incomplete application of certain procedures.
Introduction to automatic data preparation in PS CLEMENTINE PRO
The question then arises, is the analyst always condemned to tedious and difficult work at the data preparation stage? Working with PS CLEMENTINE PRO, the analyst gets a node that significantly improves and streamlines the process of working with data. This node is Auto Prepare. This node uses machine learning to identify problems with raw data and correct them before entering the modeling. As mentioned earlier, preparing data for analysis is an important and time-consuming task. The Auto Prepare node performs this task for the analyst, analyzing the data and identifying corrections, sifting out values, missing data that are problematic or unlikely to be useful for modeling, deriving new attributes where appropriate, and improving performance through intelligent data enhancement techniques.
Using PS CLEMENTINE PRO and the Auto Prepare node makes it quick and easy to prepare data for model building, without having to manually check and analyze individual variables. This results in faster model building and evaluation. In addition, using Auto Preparation increases the flexibility of automatic modeling processes, such as model refreshing.
Users can use the node in a fully automated manner, allowing the node to select and apply corrections, or the analyst can preview the changes before they are made and accept or reject them as needed. Automatic data preparation in this node recommends data preparation steps that will affect the speed at which other algorithms can build models and that will improve the predictive quality of those models.
The node allows the user to specify the model-building priorities on which the data preparation process should focus. The user can choose from four goals:
- Balancing speed and accuracy - this option allows data preparation to give equal priority to building models in a way that balances speed and accuracy of prediction.
- Optimize for speed - data preparation will be done to prioritize the speed of data processing by model building algorithms. This option should be selected when working with large data sets or looking for a quick answer.
- Optimization for accuracy - this option allows you to prepare the data so as to prioritize the accuracy of the predictions created by the model building algorithms.
- User analysis - the last option allows you to manually change the settings and adjust them to suit the analyst's requirements.
Each of these objectives will have a different use depending on the data the analyst will be working with.
Summary
Improving data quality in data preparation requires a comprehensive approach that includes identifying errors, removing duplicates, normalizing and standardizing, filling in missing values, reducing dimensionality or categorizing. Following these practices leads to more reliable and valuable analytical results and better machine learning models.
However, it is worth remembering that manual data preparation comes with many challenges, such as lack of scalability, lack of standardization, human error or required expertise. Using a manual approach is labor-intensive and can lead to problems with the quality and efficiency of data preparation.
Therefore, it is important to use solutions that make the work easier when working with large data sets. Helping in this regard is the Auto Prepare node, which gives the analyst the ability to specify one of three data preparation goals or choose his own settings and supply them accordingly to the statistical models being built.