Reading the article will take you:
7 minutes.
Scoring processes pose many challenges not least that of process flexibility, namely performing the right procedures at the right time and in cooperation with the right systems. We can rarely be completely independent from external systems and, furthermore, we always need to be cognizant of the risks involved and ready to find solutions to any potential problems that occur.
When it to comes to building flexible scoring processes, what does PS CLEMENTINE PRO 3.0 have to offer? In this article we will discuss the various ways of triggering tasks and the methods of adjusting procedures to business requirements.
Regular process automation: A task schedule
For effective use, many analytical process models require regular routine procedures to be executed. In the case of data obtained from external services, a common set of procedures that are routinely deployed are designed to ensure the data are correct before it reaches the scoring process.
In the last post we addressed the topic of acquiring current data about the COVID-19 pandemic from REST API-based external services. For companies and institutions involved in health care, such data are invaluable. Simultaneously, however, there are a number of inherent risks not least that the data are collected and published by hundreds of separate institutions from all around the world, which operate in a dynamic, intensely changing reality. In such a situation, human error at various stages of these actions are not rare. There are situations, for example, when after a few days amendments are published to the previously reported number of infections, which turned out to be wrong.
It is impossible to manually verify every day whether any of the previously published data have been updated or not. It is much simpler and more effective to create a process that will automatically verify the correctness of historical data about the pandemic as compared to those currently available from the REST API site. After creating such a stream, it would be sufficient to create and schedule a task using PS CLEMENTINE PRO Manager. The task in Fig. 1, for example, would be activated every day at 05:00.

Fig. 1. A task configured using a launch schedule
As one can see above, scheduling provides a level of flexibility in executing regular procedures – from interval-based (e.g. every 10 minutes, every hour), to weekly (e.g. on Tuesdays and Thursdays every two weeks), to monthly launch (e.g. the last day of the month in June and December, or on the first Monday every month).
The configured task does not have to consist of just a single stream – real processes are usually much more complex and consist of many stages. Tasks in PS CLEMENTINE PRO may consist of many streams, each of which is responsible for separate actions, executed in the order set in the task (see Fig. 2).

Fig. 2. A task made of several streams
Triggering tasks by a web service
So far we have looked at how to launch a task at a specific moment and how to run several consecutive streams. A task made of several streams will be effective in creating complex procedures, however, it has a certain disadvantage – this being lack of flexibility. When configuring a task in this way, we at the outset have to declare parameter settings with which the particular streams will be launched. This means that when running this procedure we can no longer change the parameters once they have been assigned. Whilst we may not need to dynamically change parameter values in the course of the process, sometimes it is necessary to do so.

Fig. 3. Stream launch parameter configuration window
Let's say that within the data quality control process we would not only like to retrospectively verify their correctness, but also assess whether some of the data we have received as part of the current “top-up” do not look suspicious. Let's assume that we receive from a data service today's data about new infection cases in Germany, and it turns out that they are negative instead of positive. Should we without question enter them into our systems and use for scoring? Whilst we gaze with envy at our neighbors who have high quality health care, maybe that data are not providing us with a complete picture. To protect against such situations we can create a task that verifies the received data for potential errors on a regular basis e.g. a set of rules that the data must fulfill to be considered satisfactory (see Fig. 4).

Fig. 4. Nodes defining a set of sample rules to evaluate suspicious records
Data not meeting these rules are selected and sent for further verification using another task. This is achieved by taking the values in particular records and applying them as the launch parameters for another task (resulting in as many task launches as there are suspicious records). As part of this task, for each suspicious record the data obtained from the initial service can be compared with the data available on another service. If it turns out that other services provides more credible data – this data can be used in place of the original data.
To launch a task that is responsible for this with proper parameter settings, the Web service option should be used. This allows a SOAP or REST message containing information about the expected launch parameters to be added. Fig. 5 shows the task data (in the Manager) which contains a full specification of the messages (together with the service address) which, when received, will trigger a task launch.

Fig. 5. SOAP envelope specification allowing a task launch for specific parameter values
Output PS SOAP/PS REST nodes discussed in the previous post allow a SOAP message to be sent to the so created service (it is enough to attach them at the end of our stream and configure as necessary).
Once again, let's emphasize that by using task parameters and their dynamic application to create SOAP/REST messages, we can launch the verification process only for those records that are suspicious. The other, correct records are “free” to participate in further stages of the scoring process. As a result, not only do we shorten the duration of processes, but we also avoid the unnecessary blocking of downstream procedures that would occur if we used a more "rigid" approach to creating complex tasks from many streams such as a task schedule.
However, what if none of the records have been indicated as suspicious and our node does not send any message further?
Conditional execution of steps
PS CLEMENTINE PRO 3.0 provides a further flexible approach to the processes being created. This requires special attention to be paid to stream scripts, which, in cooperation with the Python-based Modeler API, guarantee very high arbitrariness in controlling procedures.
Let's say that in the example being discussed in the previous paragraph we would like to distinguish between two situations:
- Our rules detected suspicious records. These were later used to create SOAP messages, which launched further tasks in order to verify correctness of the entered data and prepare them for scoring.
- Our rules did not detect any suspicious records. As a result, the PS SOAP node at the end of the stream received an empty data set, and thus did not send any message and did not launch any further task.
Focusing on scenario 2, our procedures would stop at this stage and it would be necessary to forward somehow the information about success, which would launch further actions for the preparation for scoring. One of the available possibilities would be to write a Python script, which, after the rules evaluation stage, would check whether any suspicious records have been detected or not. If no records would be detected, the script would not execute the part of the stream responsible for creating and sending the SOAP message to the further task (comparing the data with those in other services i.e. Task 1 in Fig. 6), and would only execute the task launch node following the verification stage i.e. Task 2 in Fig. 6 (thereby ignoring Task 1).

Fig. 6. Stream utilizing conditional execution of nodes
As you can see, with Python scripts it is possible to significantly extend the scope of PS CLEMENTINE PRO and adjust the system to specific situations and business conditions. In scripts, you can refer both to values of specific cells in tables (also their attributes i.e. number of rows, etc.), and to node property settings, stream parameters, global values calculated during the process, and also external values such as date or time. In order to use these possibilities, at least a basic knowledge of Python and Modeler API is necessary (you can learn more about both in PS training programs provided).
Users who do not know the Python language can utilize the option of executing streams based on conditions, implemented in the Execution tab under "Execution in a loop/conditional". However, with this option, the conditions are limited to just the value from a given cell in the table, global values or stream parameters.
Entering data by means of files
In the example above, we have described the process whereby any suspicious records are verified by automatic comparison with those available from other external service providers. However, what if these other external sources also provide information that is considered suspicious according to our rules? What if we have already used all automatic verification options and still our procedures cannot accept such data? Each such system has its boundaries – we are rarely able to automatically handle all the situations – and occasionally human engagement is necessary to ensure correct operation. In the above situation, for example, we could notify one of our company's employees about suspicious records that need to be "manually" verified for correctness. He or she having expert knowledge would, in turn, have the possibility to verify this information using sources unavailable or hardly available to IT systems, but still open for “manual” analysis e.g. unstructured data such as text at online sites, images or video. Whilst there are ways to conduct machine-based exploration of such data sources, sometimes it simply does not pay off given the diversity of the sources, or simply the relatively rare use of these tools. Sometimes it is just better to manually review several websites of public institutions, media reports or other reports than to create complex algorithms to process such data into an appropriate form and extract necessary information.
After manual verification of such information, the employee may enter them into the system. This can be achieved in many other ways e.g. by entering the data as parameters for a properly configured task, or simply by writing an SQL inquiry modifying respective tables in the database. In this regard PS CLEMENTINE PRO offers an additional option which may prove beneficial in specific situations.
Another option available in PS CLEMENTINE PRO to trigger a task is File Monitor. Tasks are launched whenever a new file appears in the designated path, or when the file name contains certain words or extensions e.g. "report" or ".csv" (see Fig. 7).
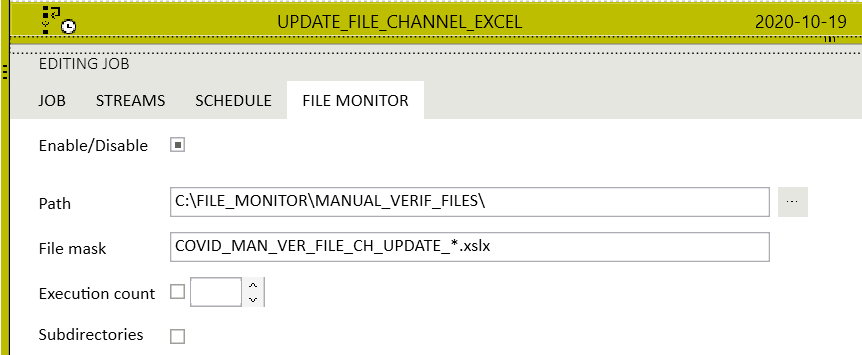
Fig. 7. Trigger type - File Monitor
Additionally, you can specify whether the file added in this way is to take part in the process being launched, or is to serve only as the task "trigger". You can enter a file to the process using a special parameter type (Fig. 8). After the end of the process you can automate file transfer to the archive by writing a short Python script in the Modeler stream.

Fig. 8. File Monitor - Paramaters
The use of this option can accelerate manual work on data entry to the system as well as protect against input errors. In addition, from the outset when designing the process, we gain full control over what procedures are to be triggered by including a file in the chosen folder. A simple action like this can start a whole sequence of processes which the employee verifying the data and preparing the file does not have to know about and does not have to have the related competences. The more elements we "take off the shoulders" of the employee, the more we reduce the risk of erroneous data entering the process leading to incorrect results reaching our scoring model.
To sum up, PS CLEMENTINE PRO 3.0 is a system whose main aim is to support process automation. It contains newly implemented functionalities that both help in the integration with external systems and increase the possibilities for adapting procedures to complex business requirements. By combining specific solution functionalities and components we can create processes that are resistant to errors and maximize chances for correct and effective use of scoring models.